Streamline your data management by bringing together information from multiple sources

As the term implies, data consolidation means bringing together data from various sources and assembling it within a single location. Data consolidation allows users to engage data from a single point of access and fosters the generation of data insights.
By consolidating your data, you eliminate silos, reduce redundancy, and create a unified view of your information assets. This approach enables more efficient data analysis, better decision-making, and improved operational efficiency across your organization.

Data consolidation empowers smarter decisions across the organization by providing unified, accessible data. It also enhances customer interactions by leveraging complete, aggregated insights.
Centralizing data helps identify inefficiencies that drive up costs, enabling smarter cost-saving strategies. Improved data quality also ensures more reliable system performance.
Centralizing data in a single repository eliminates the time wasted searching across scattered sources, allowing employees to access information quickly and work more efficiently.
Centralized and cleaned data enables faster, more effective disaster response by ensuring critical information is readily accessible during emergencies.
The most important data consolidation technique is known as ETL (extract, transform and load). ETL processes begin with ETL tools extracting information from data sources. Then that data is transformed into a standard informational format. Lastly, the data is loaded into a selected destination.
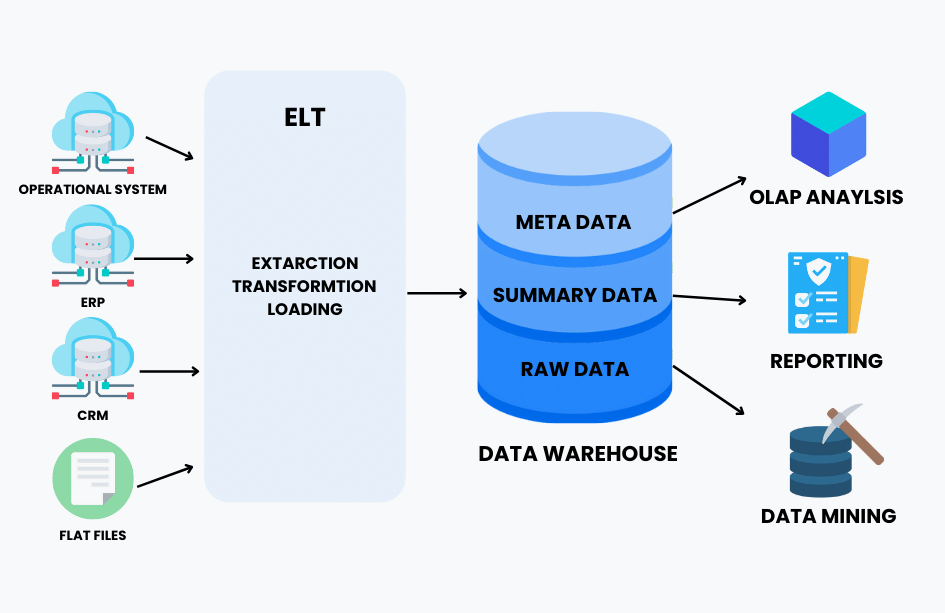
An emerging counterpart to ETL strategy is called ELT (extract, load and transform). The re-arrangement of ELT steps is crucial. In ELT, data is extracted, then loaded to a type of staging area. Data remains here as various entities within the organization study it from different angles, ultimately transforming the data.
Keeping all data in one centralized repository is a practical approach. A higher degree of data security can be achieved with the use of a data warehouse, which accepts the data sets from various source systems. ETL tools can then be used to automate data and consolidate it into the warehouse.
Data warehousing is used in part to clean or process data. A data lake, on the other hand, is simply a data repository that offers none of the data-processing capabilities. A data lake is essentially a place to park data while it's still in its rawest form. Typically, this is where a company might deposit obscure data.
It's all a matter of scale. A data warehouse is geared to accept and store all data. A data mart is simply a smaller data warehouse with a much narrower focus. So, while a company uses a data warehouse, a department or group within that company might have a data mart specific to its particular needs.
In an age of automation, hand-coding seems old fashioned. However, there are plenty of circumstances which call for a simple data consolidation job. Such work is accomplished through hand-coding, as performed by a data engineer. The code that engineer writes helps "corral" data into one location.
Yet another data consolidation solution for businesses to consider is data virtualization, wherein data stays in its existing silos and is viewed through a virtualization layer that's added to each data source. Unfortunately, there are limitations related to this method, including reduced scalability.
Data Consolidation Architecture
Our comprehensive platform architecture for modern data management